
 Tuesday, May 5, 2026 -
News
GGIR release 3.3-6
Tuesday, May 5, 2026 -
News
GGIR release 3.3-6
Friday, June 21, 2024
A new article was recently published from the project I did with Annelinde Lettink and colleagues at Amsterdam University Medical Center.
The gap in knowledge we aim to fill
For many years the field has focussed on finding useful algorithms to extract insight from raw data accelerometry. People, me inclusive, either assume that the algorithm is applicable across sensor brands and configurations given that they all store data in the same gravitational units, or we investigate comparability at algorithm output level. However, the comparability at the most fundamental level, the raw data itself, has never been studied.
How to assess comparability?
For comparing raw data between accelerometers we need to be sure that movement is 100% identical. It is impossible to attach a set of accelerometers on the exact same human body location. Neither can we expect an individual to repeatedly make the exact same body movement while wearing a different accelerometer at each repetition. Therefore, the only way to investigate the comparability at raw data level is by using mechanical movements. For this we dusted off the mechanical shaker table that I previously used during my McRoberts days in 2005-2008.
The next challenge was to get access to a sufficiently large pool of accelerometers from various brands. The pandemic lockdowns offered a solution as many research groups were not using their accelerometers. So, we asked colleagues in the field to lent us a sample of their accelerometers.
What makes this study valuable?
The results of our study reveal that raw data differs between brands in both the time and frequency domain.
However, this is not some geek project with no relevance to the real world! Awareness of differences in raw sensor data allows us to better anticipate how the output of any algorithm applied to it will be affected. And yes, this applies to any algorithm, including both machine learning techniques and domain knowledge driven approaches.
Further, understanding raw data comparability helps us to be more confident when using these algorithms across sensor brands and configurations.
Open access data and open source code
All data, code, and more detailed documentation of experiments have been shared publicly to enable reproducibility of our findings and facilitate future research. On that note, we even share additional experiments which we did not use in the published article. We did these additional experiments in the hope to maximise the potential value of the dataset.
For example, I was curious to know whether it is possible to develop an experiment that anyone can do in any research context that would be equally informative as a mechanical shaker experiment but does not require an actual mechanical shaker. So, I attached a series of accelerometers to the edge of a door and moved the door repeatedly. I know this may sound ridiculous, but what if this little experiment could help studies to identify problematic sensors? I have not had time yet to look at the data and investigate this, but maybe you do?!
Further, it may be worth highlighting that there is a video to summarise the experiments inside the documentation (credits to Annelinde for creating the video!).
If you plan to use any of the data or code and run into difficulties then do not hesitate to reach out!
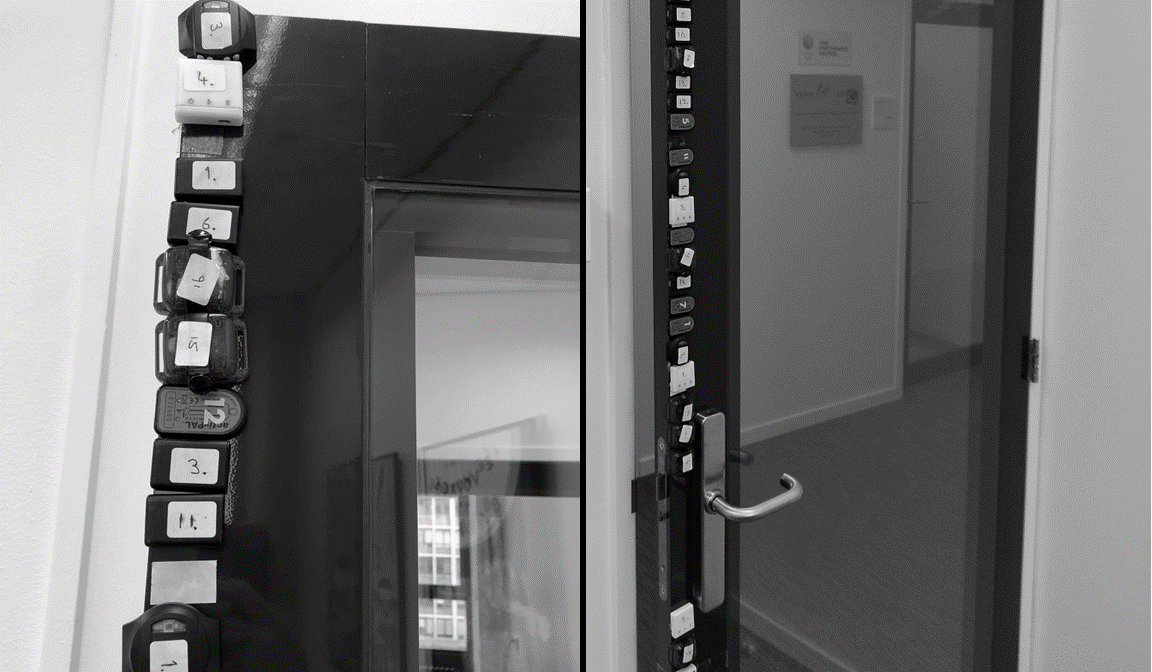
More articles
Tuesday, May 5, 2026 -
News
GGIR release 3.3-6